今天將深入了解機器學習的應用,並簡要介紹機器學習的兩大基本類型:監督式學習和非監督式學習。在這之前,該有的基本觀念還是解釋一下~
機器學習 (Machine Learning, ML) 是一種通過大量歷史數據去識別分布型態、自我學習數據之間的關係、改進自身性能以達到最佳化預測結果的技術。簡單點來說,ML 主要的目標是讓機器能夠運用算法來解析數據,從中自主的從數據中提取有價值的資訊,再基於這些資訊對未來的數據做出預測或決策。這種方法使得 ML 在處理複雜問題和大量數據時特別有效。
機器學習的應用可以在不同領域使用到,舉例一些筆者曾經使用的領域:
這些應用範圍涵蓋了從日常生活中到專業領域的各個方面,還有更多應用領域,如娛樂、零售業的客戶個性化推薦及推播系統、庫存管理、銷售預測等。
在理解機器學習的基本概念之前,我們先來看看傳統程式設計與機器學習在處理輸入(input)和輸出(output)方面的不同之處。
工程師需要明確的編寫每一步的邏輯規則,並將這些規則寫成程式碼。這些規則 定義了如何將輸入轉換為輸出。
舉例來說,如果要做一個計算機讓兩個數字相加,以下是傳統程式設計的輸入、處理及輸出:
工程師不再需要寫將輸入轉換為輸出的邏輯處理規則。我們反而是讓計算機自己學習如何從數據中找出規則。
舉例來說,近期詐騙猖獗,如果要預測新收到的手機訊息是不是詐騙,此系統的輸入、訓練及輸出如下:
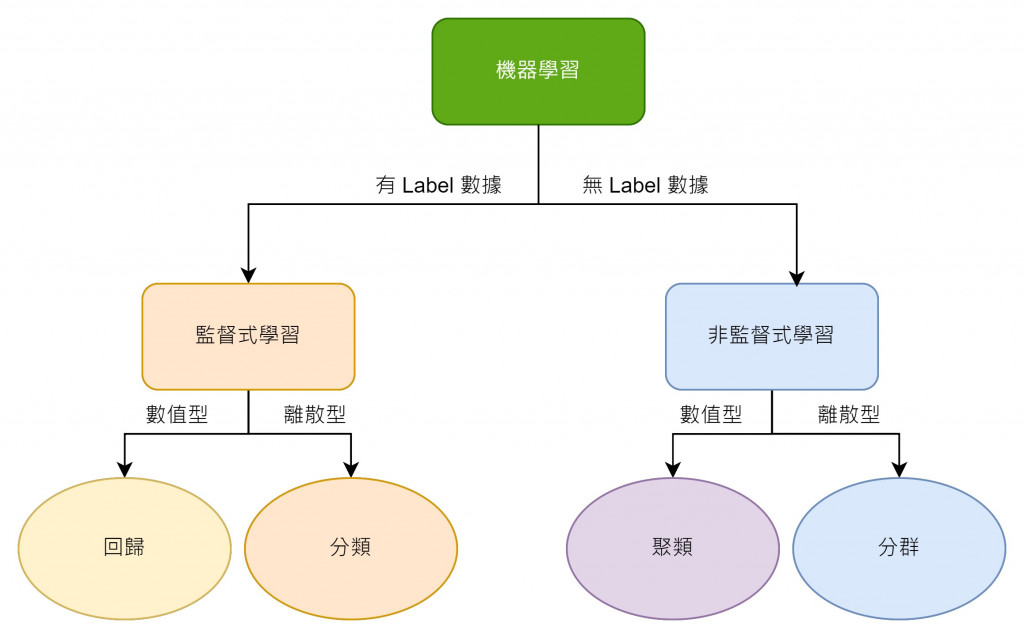
機器學習主要分成兩大類型:監督式學習 (Supervised Learning) 和非監督式學習 (Unsupervised Learning)
有 Label 的數據,也就是說你手上的數據已經有最終要預測的目標值或答案的標註, 就好比有人在一旁指導你學習,告訴你答案。只要數據中包含了最終要預測的輸出值(Output/ Prediction),則他就屬於監督式學習。例如:想要判斷病人的腫瘤屬於良性還是惡性,而數據集中已有過去病患良性/惡性腫瘤的標註
監督式學習可以進一步分為兩種主要任務:
[註記]離散值指的是有限的、可數或可列舉的數值或類別;而連續值則是一個範圍內可以取無數個不同的值,通常是一個連續區間。
無 Label 的數據,也就是說你手上的數據當中沒有最終要預測的目標值或答案的標註,就像是自學一樣,機器需要自己從數據中歸納出內在的模式和規律。如果你的問題是要對數據進行分類,而數據本身並未提供已知的分組資訊,那就屬於非監督式學習了。 例如:從100萬個不同的基因中,找到一種自動將這些基因根據不同的變量 (如壽命、位置等) 分組的方法。 其主要子類型包括:
客戶分群通常使用聚類算法,例如市場行銷中根據客戶購買行為,將客戶分成不同的群體,數據可視化則使用降維算法,例如將高維數據投影到 2D 或 3D 空間,以便觀察數據結構和分布。
[自行製圖]
要判斷機器學習任務是屬於監督學習還是非監督學習,關鍵在於數據是否帶有標記。具體可以按照以下步驟進行:
理解監督式與非監督式學習的區別,對於選擇合適的機器學習算法模型很重要。這些知識將為後續的學習和實踐打下堅實的基礎。

